Codingtagebuch
Projekt: Dokumentation zum Kurs „100 days of code - The complete python pro bootcamp“
Ich habe mir das Programmieren mit Python vor einiger Zeit selbst beigebracht. Dabei habe ich u. a. PyPy (einen JIT-Compiler) ausprobiert sowie Threads und Locks genutzt, EC2-Instanzen in Betrieb genommen und Code auf den Umgang mit APIs abgestimmt.
Abgesehen von einem abgeschlossenen Kurs in iOS-Entwicklung habe ich viele andere Kurse nur teilweise durchlaufen (Webentwicklung, Android Studio mit Java/Kotlin). Mein Wissen in Python, React, WordPress und SEO habe ich vor allem problemorientiert und praxisnah aufgebaut.
Mit der vollständigen Bearbeitung des Kurses „100 Days of Code – The Complete Python Pro Bootcamp“ möchte ich Best Practices anderer Entwickler kennenlernen und mein Verständnis strukturiert vertiefen. Statt einfach Lösungen zu reproduzieren, dokumentiere ich hier meinen Lernprozess: Beispiele, Überlegungen und kleinere Erweiterungen.
Wenn ich in den Accordion-Elementen Fixes bespreche, betrifft das Stellen im Kurs, bei denen mir Verbesserungspotenzial aufgefallen ist. Diese Anpassungen stammen von mir und sind nicht Teil des Kursmaterials (sofern ich nichts übersehen habe).
Meine Kommentare sollen zeigen, welche Probleme mir auffallen, wie ich sie analysiere und welche Lösungsansätze ich verfolge – einschließlich der Stellen, an denen bewusst Kompromisse getroffen oder Probleme offen gelassen wurden.
Der Kurs nutzt häufig input() – etwas, das ich bisher selten eingesetzt habe. Auch type() will ich künftig bewusster zum Testen nutzen.
Ich habe festgestellt, dass ich früher zu oft float-Werte für Bedingungen verwendet habe. Das will ich ändern, da Floats speicherbedingt ungenau sein können. Stattdessen plane ich, häufiger mit bool-Werten zu arbeiten.
Den Operator % nutze ich schon – er hilft z. B. beim Überprüfen von Aktualisierungen.
Im Kurs wird das Tool „Thonny“ vorgestellt, das Schritt-für-Schritt-Debugging ermöglicht. Ich halte es für hilfreich bei kleineren Tests oder unklaren Ausgaben – besonders bei Problemen, die sich durch print- oder .txt-Ausgaben schwer nachvollziehen lassen.
In komplexeren Projekten bevorzuge ich Logging mit Beispielausgaben, um Veränderungen gezielt zu prüfen.
Die Bibliothek random enthält Funktionen wie random.choice(), die ich bisher kaum verwendet habe – aber sehr nützlich finde.
range() werde ich künftig bewusster einsetzen, da es für viele Iterationen passender ist als Listen.
f-Strings sind für mich ein Gamechanger – einfacher und lesbarer als frühere String-Formate.
Bei Schleifen setze ich eher auf for und eine einzige while-Schleife, um Kontrollverlust zu vermeiden.
Ich finde es hilfreich, Variablen, die im Projekt mehrfach geändert werden können, zentral am Anfang der Datei zu definieren. Das erhöht Übersichtlichkeit und Verständlichkeit.
Bei komplexeren Abläufen werde ich künftig mit draw.io Entscheidungsbäume visualisieren, um Logik leichter nachvollziehen zu können.
Bisherige „dauerhaft laufende“ Skripte habe ich mit try / except / finally und Neustart-Logik gebaut, ohne Fehlerarten zu unterscheiden – künftig will ich spezifische Fehler (z. B. ValueError) gezielt loggen.
Rekursion war für mich bis jetzt ein eher abstrakter Begriff, den ich selbst nie verwendet habe. Erst durch den Kurs ist mir aufgefallen, dass sich damit nicht nur mathematische Probleme lösen lassen – sondern auch, dass man ein Programm oder Spiel durch einen rekursiven Funktionsaufruf ganz einfach neu starten kann.
Ein Aha-Moment für mich war folgende Struktur:
def game():
print("Willkommen im Spiel!")
# Spiel-Logik hier …
erneut = input("Möchtest du eine weitere Runde spielen? (j/n): ")
if erneut.lower() == 'j':
game()
else:
print("Danke fürs Spielen!")
# Start des Spiels
game()
Der Trick besteht darin, dass sich die Funktion game() am Ende selbst aufruft. Dadurch startet das Spiel einfach von vorne – ohne while-Schleife oder komplexe Steuerlogik.
Ich finde das Konzept elegant und leicht verständlich, wenn man es einmal gesehen hat. Gleichzeitig lerne ich, dass man bei häufiger Rekursion darauf achten sollte, nicht zu viele Aufrufe zu erzeugen – sonst droht ein Stack Overflow. Für einfache Konsolenspiele ist das aber unproblematisch.
Beim Testen eines Snake-Spiels, das mit der turtle-Bibliothek in Python umgesetzt wurde, fiel auf: Die zufällig erzeugte Position des „Food“-Objekts war oft leicht versetzt zum Raster der Schlange. Das erschwerte das visuelle Erfassen – die Schlange konnte das Futter zwar technisch erreichen, jedoch nicht exakt mittig treffen.
Ursache war die bisherige Koordinatenlogik:
random_x = random.randint(-280, 280)
random_y = random.randint(-280, 280)Diese ließ beliebige Koordinaten zu – auch Werte wie (175, 123), obwohl sich die Schlange nur in 20er-Schritten über das Spielfeld bewegt.
Die Lösung bestand darin, die zufällige Platzierung des Futters an das Grid der Schlange anzupassen. Statt pixelgenauer Koordinaten wird nun innerhalb des Spielfelds gezielt auf 20er-Stellen multipliziert:
random_x = random.randint(-14, 14) * 20
random_y = random.randint(-14, 14) * 20Ergebnis: Futter und Snake bewegen sich nun synchron auf demselben Raster. Die Positionierung wirkt aufgeräumt und das Spielerlebnis ist deutlich intuitiver.
Diese kleine Anpassung ist ein gutes Beispiel für das Zusammenspiel von visuellem Feingefühl und koordinatenbasierter Logik – und zeigt, wie sich mit wenigen Zeilen Code ein klarer Mehrwert für den User erzielen lässt.
Beim Testen eines Snake-Spiels, das mit der turtle-Bibliothek in Python umgesetzt wurde, fiel auf:
Die bisherige Input-Logik erlaubte es, vor dem nächsten sichtbaren Frame beliebig viele Richtungsänderungen auszuführen.
Dadurch konnte sich die Schlange bereits selbst beißen, bevor die Bewegung überhaupt auf dem Bildschirm dargestellt wurde.
Ursprüngliche Logik:
screen.onkey(snake.up, "Up")
screen.onkey(snake.down, "Down")
screen.onkey(snake.left, "Left")
screen.onkey(snake.right, "Right")Diese Eingabe wird unmittelbar ausgeführt — auch mehrfach innerhalb eines einzelnen Frames. Die Lösung besteht darin, Eingaben nicht sofort anzuwenden, sondern zunächst zwischenzuspeichern und erst beim nächsten Frame zu übernehmen.
snake.pending_dir = None # Eingabepuffer
def is_opposite(a, b):
# a/b sind Winkel: 0=Right, 90=Up, 180=Left, 270=Down
return (a - b) % 360 == 180
def queue_dir(deg):
# nur den ERSTEN Input bis zum nächsten Frame annehmen
if snake.pending_dir is None:
# 180°-Wende verhindern
if not is_opposite(deg, snake.head.heading()):
snake.pending_dir = deg
# Eingaben werden jetzt gepuffert statt sofort ausgeführt
screen.onkey(lambda: queue_dir(90), "Up")
screen.onkey(lambda: queue_dir(270), "Down")
screen.onkey(lambda: queue_dir(180), "Left")
screen.onkey(lambda: queue_dir(0), "Right")
Der Ablauf funktioniert wie folgt: Wird eine Pfeiltaste gedrückt, wird die gewünschte Richtung (deg) an die Funktion queue_dir übergeben.
Dort wird zuerst geprüft, ob snake.pending_dir bereits eine Richtung enthält. Ist dies nicht der Fall, wird mit der Funktion
is_opposite kontrolliert, ob die neue Richtung dem aktuellen Orientierungswinkel des Schlangenkopfs
(snake.head.heading()) genau entgegengesetzt wäre. Die Berechnung (a - b) % 360 stellt dabei sicher,
dass sowohl positive als auch negative Differenzen korrekt auf einen Winkel zwischen 0 und 359° normalisiert werden.
Nur wenn die neue Richtung keine 180°-Wende darstellt, wird sie in snake.pending_dir gespeichert und
beim nächsten Frame angewendet.
Verwendung der Eingabe im Game-Loop:
screen.update()
time.sleep(0.1)
# genau EIN Richtungswechsel pro Frame anwenden
if snake.pending_dir is not None:
new_heading = snake.pending_dir
snake.pending_dir = None
# Sicherheitscheck doppelt hält besser
if not is_opposite(new_heading, snake.head.heading()):
snake.head.setheading(new_heading)
Hier wird die zwischengespeicherte Richtung erst beim nächsten Frame angewendet. Dadurch kann die Schlange sich nicht mehr durch schnell aufeinander folgende Inputs selbst überholen oder direkt um 180° wenden.
Nachteil der Lösung: Eingaben nach dem ersten gespeicherten Input werden verworfen, solange der Frame noch nicht aktualisiert wurde. Eine mögliche Erweiterung wäre eine Eingabe-Warteschlange (Queue), aus der pro Frame nur ein Element abgearbeitet wird. Dabei müsste die Queue beim Neustart des Spiels geleert werden, um veraltete Inputs zu vermeiden.
In einem mit der turtle-Bibliothek umgesetzten „Turtle-Crossing“-Spiel wurde die Kollisionserkennung mit seitlich einfahrenden Autos nicht immer zuverlässig erkannt.
Mögliche Ursachen sind ein konservativer Kollisionsradius (20) und die relativ grobe Aktualisierungsrate (ca. 10 FPS). Mit steigender Fahrzeuggeschwindigkeit kann es so zum „Durchrauschen“ kommen (Tunneling).
#Alte Kollisionserkennung
for car in car_manager.all_cars:
if car.distance(player) < 20:
game_is_on = False
scoreboard.game_over()Minimaler Fix: Kollisionsradius etwas erhöhen und die Kollision pro Schleifendurchlauf zweimal prüfen (vor und nach dem Bewegen der Autos). Außerdem nach Game Over die Eingabe deaktivieren und den Frame hart beenden.
COLLISION_RADIUS = 25
time.sleep(0.08)
# 1) Kollision vor dem Bewegen prüfen (seitliches Reinkommen)
for car in car_manager.all_cars:
if car.distance(player) < COLLISION_RADIUS:
scoreboard.game_over()
screen.update()
screen.onkey(None, "Up")
game_is_on = False
break
if not game_is_on:
break
car_manager.create_car()
car_manager.move_cars()
# 2) Kollision nach dem Bewegen prüfen (Tunneling abfangen)
for car in car_manager.all_cars:
if car.distance(player) < COLLISION_RADIUS:
scoreboard.game_over()
screen.update()
screen.onkey(None, "Up")
game_is_on = False
break
if not game_is_on:
break- Größerer Radius: von 20 auf 25 – seitliche Berührungen werden verlässlicher erfasst.
- Mehr Prüfungen: zweimal pro Schleife, effektiv ~25 Kollisionsprüfungen pro Sekunde (bei
sleep(0.08)). - Reihenfolge: Prüfung vor und nach der Fahrzeugbewegung beugt „Überspringen“ vor.
- Eingabe sperren:
screen.onkey(None, "Up")verhindert Bewegung nach Game Over. - Harter Stopp:
breakbeendet diefor- und die laufendewhile-Iteration sofort.
Ergebnis: Robustere (aber nicht perfekte) Kollisionserkennung ohne grundlegende Strukturänderungen. Für eine noch präzisere Lösung bieten sich zwei Ansätze an: (1) rechteckige Hitboxen verwenden (Überlappung prüfen statt nur eine Distanzschwelle), und (2) nicht nur Momentaufnahmen pro Frame prüfen, sondern verfolgen, ob sich die Hitboxen während der Bewegung zwischen zwei Frames überschneiden (Continuous Collision Detection).
Projekt: Entwicklung von Webseiten
Im Rahmen der Erstellung meiner persönlichen Portfolio-Webseite wurden folgende Schritte durchgeführt:
- Aufsetzen einer responsiven Seite mit HTML, CSS & Bootstrap ohne CMS wie WordPress
- Sticky Navigation mit aktiven Seitenindikatoren
- Integration von Projekten mit automatisch startenden Videos bei Hover & Lightbox
- Barrierefreies Video-Markup durch
title-Attribute undposter-Vorschaubilder - Einbindung grafischer Linien und animierter Formen
- Implementierung von Icons, Ladeanimationen und Scroll-Top-Button
- SEO-Metadaten (Title, Description, Canonical, Open Graph, etc.) wurden in allen HTML-Dateien ergänzt
- Verwendung von semantisch benannten Dateinamen für Bilder und Videos
- robots.txt und sitemap.xml wurden erstellt
- Ein einheitliches, ruhiges Farbschema mit dezenten Animationen wurde umgesetzt
- Google Lighthouse Check erfolgreich durchgeführt (SEO: 100 Punkte)
→ Der Test wurde exemplarisch an der Startseite (index.html) durchgeführt. Viele Verbesserungen wie WebP-Bilder mit Fallback, passende Größenangaben und Minifizierung wirken sich jedoch auch positiv aufprojekte.htmlundcodingtagebuch.htmlaus. Weitere Detailoptimierungen sind dort optional möglich. - Indexierung über Google Search Console erfolgt
→ Die Webseite wurde bei der Google Search Console angemeldet und erfolgreich zur Indexierung übermittelt. Eine erneute Einreichung wäre nach umfangreichen Änderungen sinnvoll – wird von Google aber auch regelmäßig automatisiert angestoßen.
Was noch aussteht:
- Google Lighthouse Checks für alle weiteren Seiten durchführen und Verbesserungen einpflegen
- Optional: Minifizierung von CSS und JavaScript-Dateien zur Verbesserung der Ladezeit
Hinweis: Die Download-Funktion für Videos wurde aus Designgründen entfernt, um die Nutzerführung und Ladegeschwindigkeit zu optimieren.
Im Rahmen dieses Projekts wurde eine datenschutzfreundliche und interaktive Informationsplattform realisiert:
- Frontend-Entwicklung mit React, Vite und eingebundenem Bootstrap
- Integration von Server-Side Rendering (SSR) zur Auslieferung optimierter HTML-Inhalte
- Strukturierung der Inhalte durch wiederverwendbare React-Komponenten (z. B. Hinweisboxen, Accordion-Elemente, Umfragen)
- Backend mit Node.js und Express zur Bereitstellung einer REST-API
- Anbindung an MongoDB Atlas zur persistenten Datenspeicherung von Umfrageergebnissen
- Implementierung eines Fingerprint-basierten Abstimmungsschutzes und Redis-gestütztes Rate Limiting (über
rate-limit-redis) - Cloudflare als Proxy- und Sicherheitsebene vor dem Render-Hosting
- Deployment über Render
- Responsives Design
- Einbindung semantischer Meta-Daten (SEO, Open Graph, Twitter Cards) und Robots/Sitemap-Konfiguration
- Keine Cookies oder eingebundenen Tracker – Cloudflare und Render verarbeiten Zugriffe jedoch technisch bedingt
Was noch aussteht:
- Weitere Modularisierung und Purging von CSS-Klassen zur Reduzierung der Gesamtgröße
- Lighthouse-Checks und weitere SEO-Optimierung
- Ggf. erneute SCSS Integration, die beim Umstieg von CSR auf SSR vorläufig rückgängig gemacht wurde
- Vollständige Bereingung des Codes bzgl. Tailwind, welches beim Umstieg von CSR auf SSR entfernt wurde
Hinweis: Aufgrund des breiten technischen Spektrums sowie der Vielzahl paralleler Anforderungen (z. B. Sicherheit, Performance, Barrierefreiheit, Datenschutz) wurden bei der Entwicklung unterstützende Tools wie z. B. KI-basierte Assistenzsysteme eingesetzt. Gerade bei komplexeren Hürden erfolgte die Einarbeitung häufig problemorientiert – mit pragmatischem Fokus auf Lösungsfindung und inkrementellem Fortschritt.
Projekt: Software-Testing (automatisiert)
Um mein Verständnis für Softwaretests zu vertiefen, habe ich mit dem Robot Framework in Kombination mit Selenium erste Tests erstellt – direkt anhand meiner eigenen Webseite. Dabei habe ich verschiedene Testarten wie Smoke-, System- und Akzeptanztests umgesetzt.
Mir gefällt, wie strukturierte Klarheit auf flexible Erweiterbarkeit trifft: Die Testsprache von Robot ist gut lesbar, eignet sich durch die Python-Integration aber auch für komplexere Anwendungsfälle. Ergänzt durch die SeleniumLibrary kann ich gezielt mit Webseiten interagieren – etwa Formulare ausfüllen, Inhalte überprüfen oder Klicks simulieren.
Für mich war das eine spannende Erfahrung, bei der ich automatisiertes Testing nicht nur theoretisch, sondern wirklich praktisch erfahren habe.
In der Softwareentwicklung unterscheidet man verschiedene Arten von Tests, um Qualität und Funktionalität sicherzustellen:
- Smoke-Test: Ein Smoke-Test stellt bspw. sicher, dass die Webseite fehlerfrei im Browser geöffnet werden kann, ihre Navigation sichtbar ist und das Schließen des Browsers keine Fehler verursacht.
- Unit-Test: Test einzelner Funktionen oder Methoden isoliert vom Gesamtsystem.
- Integrationstest: Prüft das Zusammenspiel mehrerer Komponenten (z. B. Datenbank und API).
- Systemtest: Test eines vollständigen Ablaufs unter realistischen Bedingungen – z. B. das Ausfüllen und Absenden eines Formulars mit anschließender Weiterleitung auf eine Bestätigungsseite.
- Akzeptanztest: Prüfung, ob die Anwendung so funktioniert, wie es Nutzende oder Projektverantwortliche erwarten – etwa in Bezug auf Inhalte, Funktionen oder gesetzliche Anforderungen.
- Regressionstest: Sicherstellung, dass bestehende Funktionalität durch neue Änderungen nicht unbeabsichtigt beeinflusst wird.
- Explorativer Test: Testen ohne vorher festgelegte Abläufe, bei dem die Anwendung gezielt und kreativ erkundet wird – mit dem Ziel, Fehler und unerwartetes Verhalten aufzudecken.
- Performanztest: Überprüfung der Ladezeit, CPU-Auslastung und Rendering-Zeiten, z. B. mit Google Lighthouse.
- Kompatibilitätstest: Sicherstellen, dass die Webseite in verschiedenen Browsern und auf verschiedenen Geräten konsistent dargestellt wird.
Ein Smoke-Test stellt sicher, dass grundlegende Funktionen der Webseite bereitstehen. Beispielsweise:
- Öffnet sich die Webseite korrekt?
- Ist ein zentrales Navigationselement wie „Überblick“ im Seiteninhalt sichtbar?
*** Settings ***
Library SeleniumLibrary
*** Variables ***
${URL} https://www.lukas-kauzmann.com
*** Test Cases ***
Google Öffnet Erfolgreich
Open Browser ${URL} chrome
Wait Until Page Contains Überblick 5s
Close Browser
Der Akzeptanztest prüft, ob rechtliche Anforderungen im Impressum eingehalten werden:
- Sind Pflichtparagraphen wie
§ 5 TMGund§18 Abs. 2 MStVenthalten? - Sind die erforderlichen Angaben im sichtbaren Text enthalten?
*** Settings ***
#Library BuiltIn
Library SeleniumLibrary
*** Variables ***
${URL} https://www.lukas-kauzmann.com/impressum.html
*** Test Cases ***
Impressum Enthält Pflichtangaben
Open Browser ${URL} chrome
Maximize Browser Window
# Warte auf das Impressums-Element
Wait Until Element Is Visible xpath=//section[contains(@class, "impressum-section")] 5s
${text}= Get Text xpath=//section[contains(@class, "impressum-section")]
Log >>> GEFUNDENER TEXT <<<\n${text}
Log To Console >>> GEFUNDENER TEXT <<<\n${text}
#${count}= Evaluate text.count("§") text=${text}
#${count}= Convert To Integer ${count}
#${count}= Evaluate """${page}.count('§')"""
# Workaround: schreibe Text in temporäre Datei, dann zähle in Python
${count}= Evaluate __import__('re').findall("§", """${text}""").__len__()
IF $count < 2
Fail Es wurden nur ${count} Paragraphenzeichen gefunden
END
# Prüfen auf wichtige Nummern
Should Contain ${text} 5
Should Contain ${text} 18
# Check auf "Absatz" oder "Abs."
${result_abs}= Run Keyword And Ignore Error Should Contain ${text} Absatz
${result_abs2}= Run Keyword And Ignore Error Should Contain ${text} Abs.
IF '${result_abs[0]}' != 'PASS' and '${result_abs2[0]}' != 'PASS'
Fail Absatz/Abs. fehlt
END
# Check auf "TMG" oder "Telemediengesetz"
${result_tmg}= Run Keyword And Ignore Error Should Contain ${text} TMG
${result_tmg2}= Run Keyword And Ignore Error Should Contain ${text} Telemediengesetz
IF '${result_tmg[0]}' != 'PASS' and '${result_tmg2[0]}' != 'PASS'
Fail TMG fehlt
END
# Check auf "MStV" oder "Medienstaatsvertrag"
${result_mstv}= Run Keyword And Ignore Error Should Contain ${text} MStV
${result_mstv2}= Run Keyword And Ignore Error Should Contain ${text} Medienstaatsvertrag
IF '${result_mstv[0]}' != 'PASS' and '${result_mstv2[0]}' != 'PASS'
Fail MStV fehlt
END
Log Impressum enthält alle wichtigen Paragraphen
Close Browser
Der Systemtest bezieht sich auf das Kontaktformular:
- Eingabefelder werden korrekt angezeigt und validiert
- Die Formulardaten werden korrekt übermittelt
- Die Bestätigungsseite enthält korrekt dargestellte Sonderzeichen (z. B. „ü“)
- Der "Zurück zur Startseite"-Link funktioniert
*** Settings ***
Library SeleniumLibrary
*** Variables ***
${URL} https://www.lukas-kauzmann.com
*** Test Cases ***
Kontaktformular Funktioniert und Bestätigungsseite Zeigt Umlaute
Open Browser ${URL}/impressum.html chrome
Maximize Browser Window
Wait Until Element Is Visible id=name 5s
# Formular ausfüllen
Input Text id=name Jürgen Mustermann
Input Text id=email "E-Mail-Adresse"
Input Text id=message Dies ist ein Test mit einem Umlaut: ü
Scroll Element Into View xpath=//button[@type='submit']
Click Button xpath=//button[@type='submit']
# Warte auf Weiterleitung zur Danke-Seite
Wait Until Location Contains danke.html 5s
# Prüfe, ob das "ü" korrekt angezeigt wird
Page Should Contain ü
# Zurück zur Startseite navigieren (wenn ein Button oder Link vorhanden ist)
Click Link Zurück zur Startseite
# Prüfen, ob Startseite erreicht wurde
Wait Until Page Contains Überblick 5s
Log Kontaktformular und Weiterleitung funktionieren einwandfrei
Close Browser
Während der Testentwicklung sind mir einige typische Herausforderungen begegnet, die ich durch gezielte Workarounds lösen konnte:
-
Probleme bei der Textauswertung mit
Evaluate: Beim Zählen von Paragraphenzeichen („§“) im Impressum wurde trotz sichtbarer Inhalte mehrfach der Wert0zurückgegeben. Die Ursache lag darin, dass nicht der gesamte sichtbare Text korrekt übergeben wurde. Durch präzise Auswahl der richtigenxpath-Section und zusätzliche Ausgabe des Textes in der Konsole konnte ich verifizieren, dass die richtigen Inhalte abgegriffen wurden. Zunächst ließ sich die Anzahl der Paragraphenzeichen (‚§‘) im Text nicht zuverlässig zählen – weder mit einfachen Zählbefehlen noch durch direkte Übergabe des Textes an Evaluate. Deshalb wurde ein Workaround genutzt: Der Textinhalt wurde in eine temporäre Python-Umgebung übergeben, in der ein regulärer Ausdruck (also ein Suchmuster für bestimmte Zeichen) eingesetzt wurde, um alle Vorkommen von „§“ zu zählen – unabhängig von Zeilenumbrüchen oder Formatierungen. So konnte der Inhalt korrekt und robust überprüft werden. -
Kombinierte Bedingungen mit
Evaluate: Mehrfachversuche, Bedingungen wie"Absatz" in text or "Abs." in textdirekt perEvaluateauszuwerten, führten zu Syntaxfehlern – vor allem bei größeren Texten mit Sonderzeichen. Stattdessen wurde ein robusterer Ansatz gewählt: mitRun Keyword And Ignore Errorwurde für beide Varianten geprüft, ob ein Begriff enthalten ist. Die Ergebnisse wurden dann mit einemIF-Block interpretiert. -
Timing-Probleme beim Seitenaufbau: Gerade bei Weiterleitungen oder dynamischem Laden von Inhalten (z. B. nach dem Absenden des Kontaktformulars) trat das Problem auf, dass der Test zu schnell weiterlief. Durch gezielte Verwendung von
Wait Until Element Is Visiblebzw.Wait Until Page Containskonnte sichergestellt werden, dass erst geprüft wird, wenn die Seite vollständig bereit ist. -
Fehler beim Klick auf Buttons (ChromeDriver): In einem Fall wurde beim Klick auf den Submit-Button ein
ElementClickInterceptedExceptionausgelöst. Ursache war, dass der Button noch außerhalb des Viewports lag. Die Lösung bestand darin, das Element vorher perScroll Element Into Viewsichtbar zu machen, um es danach zuverlässig klicken zu können.
Diese Herausforderungen haben mir gezeigt, dass auch einfache Tests durch technische Details beeinflusst werden können – und mir erneut vor Augen geführt, wie wichtig es ist, strukturiert zu debuggen und flexibel zu reagieren.
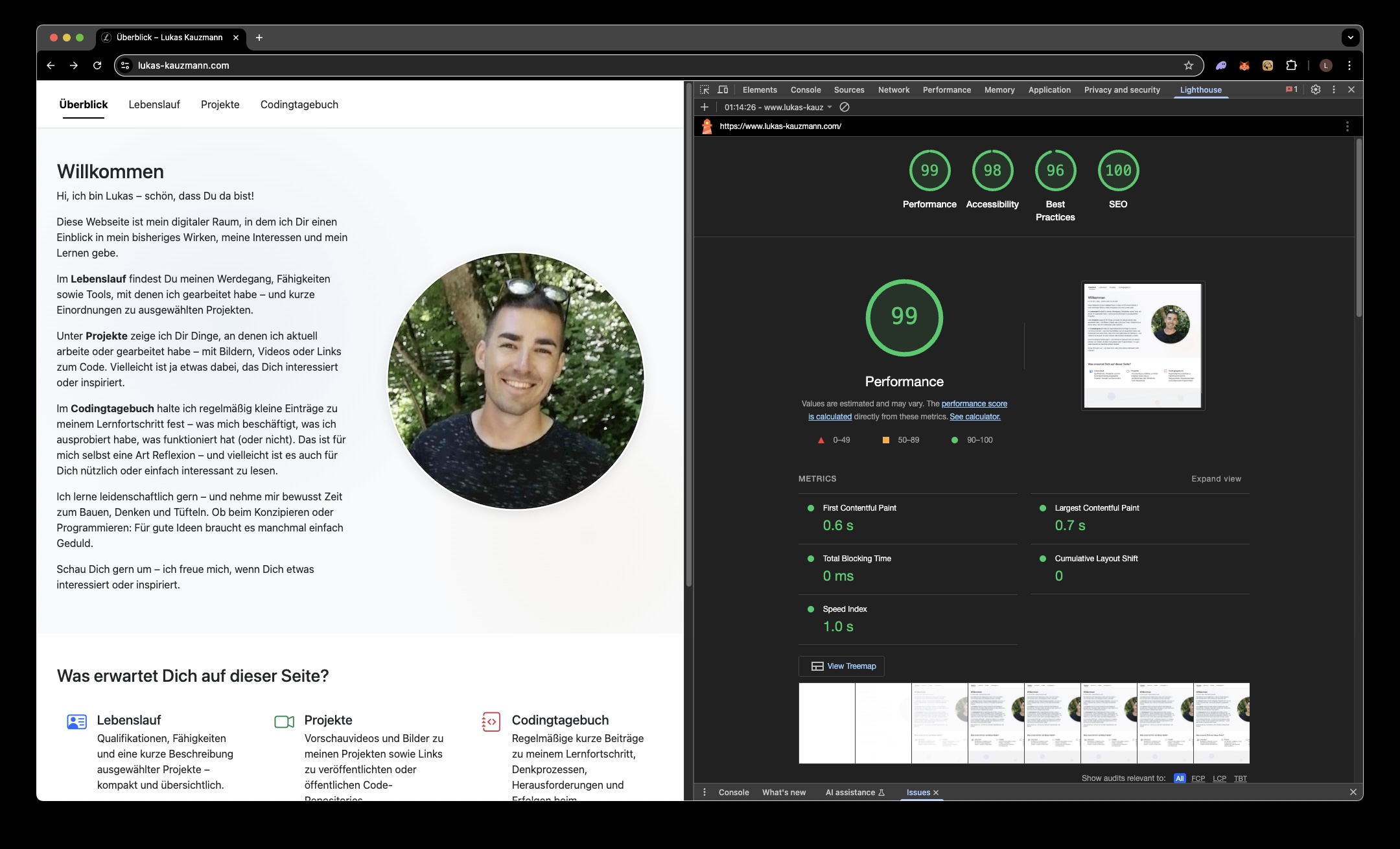
Zur Verbesserung der Performance, Barrierefreiheit und Suchmaschinenoptimierung habe ich gezielte Tests mit Google Lighthouse durchgeführt.
Die Ergebnisse wurden systematisch analysiert und schrittweise umgesetzt – mit dem Ziel, technische Schwachstellen zu beseitigen und Best Practices zu etablieren.
- Entfernung des initialen Page-Loaders, der zu Ladeproblemen führte
- Einführung eines dezenten
fade-in-Effekts zur Verbesserung der UX ohne Render-Blockierung - Ersetzung klassischer Bildformate durch moderne WebP-Dateien mit JPEG-Fallback
- Skalierung der Bildgrößen passend zur tatsächlichen Darstellung im Frontend (z. B. 400 × 400 px)
- Integration von
preconnectfür externe Ressourcen wie Google Fonts und CDN-Links - Validierung und technische Korrektur der
canonical-Tags mittels Weiterleitung via.htaccess - Minifizierung von CSS-Dateien zur Reduktion der Ladezeit (kein Einsatz von PurgeCSS, da essenzielle Klassen entfernt wurden)
Ein bestehendes Warnsignal zum Thema eval()-Verwendung wurde bewusst nicht behandelt, da Lighthouse lediglich den Einsatz bestimmter Methoden wie setTimeout("code") beanstandet – nicht aber sichere Varianten mit Funktionen (wie bei dieser Seite).
Der empfohlene Ansatz bei der Nutzung von Lighthouse: Zuerst die roten Probleme (kritische Fehler) beheben, anschließend gezielt gelbe Hinweise (Optimierungspotenziale) angehen. Die grauen Tipps sind optional, aber oft hilfreich für langfristige Wartbarkeit oder UX-Aspekte.
Das aktuelle Ergebnis: 100 Punkte im Bereich SEO – bei stabiler, semantisch klarer Umsetzung und guter Nutzerführung.
Um die Darstellung und Bedienbarkeit auf verschiedenen Endgeräten zu überprüfen, habe ich manuelle Kompatibilitätstests durchgeführt. Ziel war es, visuelle Inkonsistenzen und Abweichungen im responsiven Verhalten zu identifizieren.
Getestete Kombinationen:
- Safari (Mac, WQHD-Auflösung)
- Chrome (Mac & mobil simuliert via DevTools)
- Chrome (Android Smartphone)
- Responsively App zur simultanen Geräteansicht (iPhone, iPad, Mac)
Beobachtungen:
- Index.html (Safari, Mac): Links neben den Icons erscheinen bei der Animation feine Linien, die in anderen Browsern nicht auftreten – vermutlich rendering-spezifisch für Safari.
- Profilbild: In iPhone- und iPad-Ansicht wird das runde Bild sichtbar oval verzerrt – besonders deutlich auf iPad-Bildschirmgrößen.
- Navigation (mobil): Der Link „Codingtagebuch“ springt bei kleinen Viewports als einziger in die zweite Zeile der Navigation – hier wäre ein kleiner Layout-Fix sinnvoll.
- Projekte.html (mobil): Auf Smartphones verschwinden die leichten horizontalen Versätze zwischen Projekten. Dadurch wirken Titel und Videos etwas gestaucht, die Abstände zu den Folgetiteln sind sehr knapp.
- Codingtagebuch.html (mobil): Das eingebundene Lighthouse-Bild bei den Performanztests ist auf kleinen Displays schwer lesbar. Ein Zoom- oder Lightbox-Mechanismus könnte hier Abhilfe schaffen.
- Kontaktformular: Der Funktionstest auf mobilen Geräten wurde vorerst ausgelassen und wird ggf. separat nachgeholt.
Fazit: Die Webseite ist auf allen getesteten Geräten funktional und weitgehend responsiv. Einzelne Darstellungsdetails wie runde Bilder, Abstände bei Mobilansicht oder Safari-spezifische Artefakte sollten in künftigen Optimierungsrunden angepasst werden.
Projekt: Software-Testing mit Java & Appium
Java ist eine objektorientierte Programmiersprache, in der praktisch alles innerhalb von Klassen organisiert ist. Anders als in Python, wo man schnell auch ohne Klassen arbeiten kann, beginnt in Java jedes ausführbare Programm mit mindestens einer Klasse – typischerweise einer, die eine main()-Methode enthält.
Wenn ich Methoden aus einer anderen Klasse verwenden möchte, spielen zwei Dinge eine Rolle:
- Sichtbarkeit: Die Methode muss als
publicdeklariert sein, damit sie von anderen Klassen aufgerufen werden kann. - Statisch oder nicht statisch: Eine Methode muss nur dann
staticsein, wenn ich sie ohne Objekt aufrufen möchte – zum Beispiel aus der statischenmain()-Methode heraus.
Ist die Methode nicht statisch, erzeugt man zuerst ein Objekt der entsprechenden Klasse, um sie aufzurufen:
Java unterstützt Vererbung über das Schlüsselwort extends. Dadurch übernimmt eine Klasse alle öffentlichen und geschützten Methoden der Elternklasse. Der Zugriff auf Elternmethoden – insbesondere auf den Elternkonstruktor – erfolgt wie in Python über super(). Methoden müssen nicht static sein, um vererbt zu werden – Vererbung und Static sind zwei völlig unterschiedliche Konzepte.
Konstruktoren spielen eine zentrale Rolle: In Java heißen sie genauso wie die Klasse und haben keinen Rückgabetyp. Damit entsprechen sie funktional der __init__-Methode in Python, die ebenfalls beim Erzeugen eines Objekts automatisch ausgeführt wird.
Ein wichtiger Unterschied: Java unterstützt Overloading. Das bedeutet, dass mehrere Konstruktoren parallel existieren können – zum Beispiel einer ohne Parameter, einer mit int und einer mit String. Die richtige Variante wird automatisch anhand der übergebenen Argumente ausgewählt. Python hingegen besitzt nur eine einzige __init__-Methode.
public class Person {
public Person() {
System.out.println("Standard-Konstruktor");
}
public Person(String name) {
System.out.println("Name: " + name);
}
public Person(int age) {
System.out.println("Alter: " + age);
}
}
Ein weiterer grundlegender Aspekt: Java ist streng typisiert. Der Datentyp einer Variablen muss immer explizit angegeben werden – sowohl beim Deklarieren von Variablen als auch bei Parametern in Methoden. Während Python Datentypen dynamisch zur Laufzeit bestimmt, legt Java sie bereits zur Compile-Zeit fest. Das sorgt für mehr Sicherheit und weniger Überraschungen, allerdings auch für mehr Schreibarbeit zu Beginn.
Zusammengefasst lerne ich in diesem Abschnitt vor allem:
- Wie Klassen, Objekte, Methoden und Konstruktoren zusammenhängen,
- wie Vererbung funktioniert
- und wie streng Java bei Datentypen ist – im Gegensatz zu dynamischen Sprachen wie Python.
Für meine mobile Testautomatisierung nutze ich ein Set aus zusammenhängenden Werkzeugen, die gemeinsam eine vollständige Entwicklungs- und Testumgebung bilden. Die eigentliche Testlogik schreibe und verwalte ich in Eclipse unter Verwendung von TestNG. Der Appium Server wird bei mir manuell über die Eingabeaufforderung gestartet, während ich den Appium Inspector nutze, um die UI-Hierarchie der App zu analysieren sowie relevante Locator-Strategien zu finden.
Als Testgerät verwende ich einen Android-Emulator aus Android Studio. Dieser Emulator bildet ein vollständiges virtuelles Smartphone ab und ermöglicht realistische App-Interaktionen ohne physisches Gerät.
Um neue Apps im Emulator zu installieren, gehe ich folgendermaßen vor: Zuerst starte ich den Emulator, suche anschließend im Android SDK den Ordner platform-tools, in dem sich die adb.exe befindet, und öffne dort die Eingabeaufforderung. Die Installation der App erfolgt über den Befehl adb install <Pfad_zur_APK>. Dadurch wird die entsprechende .apk-Datei direkt auf das virtuelle Gerät übertragen und dort installiert.
Zusätzlich füge ich dieselbe .apk-Datei in den resources-Ordner meines Java-Projekts in Eclipse ein. Die Datei ist damit sauber im Projekt eingeordnet und jederzeit auffindbar.
Für die Automatisierung nutze ich eine Basisklasse, die von allen Testklassen geerbt wird. Diese „BaseTest“-Struktur ist typisch für TestNG-Projekte: Sie stellt sicher, dass grundlegende Initialisierungsschritte zentral an einer Stelle ausgeführt werden, bevor ein Test startet. Dadurch wird vermieden, dass jede Testklasse erneut alle Einstellungen für Appium konfigurieren muss.
Im Rahmen dieser Basisklasse definiere ich zunächst die beiden wichtigsten Objekte meiner Testumgebung: den Appium-Treiber für die Gerätekommunikation sowie den Appium-Dienst selbst, der den Server-Prozess repräsentiert. Diese Instanzen stehen anschließend allen Testklassen automatisch zur Verfügung.
Die Initialisierung erfolgt über eine Methode, die mit @BeforeClass gekennzeichnet ist. Diese Annotation stammt aus TestNG und besagt, dass die entsprechende Methode vor allen Testmethoden einer Klasse ausgeführt wird. Hier wird der Appium-Server konfiguriert, die Verbindung zum Emulator aufgebaut und der Treiber so vorbereitet, dass er Befehle an das mobile Gerät weiterleiten kann. Zusätzlich werden die gewünschten Optionen gesetzt, zum Beispiel welches Gerät simuliert wird oder welche App gestartet werden soll.
Ebenso wichtig ist die Methode mit der Annotation @AfterClass. Diese wird von TestNG nach Abschluss aller Tests einer Klasse ausgeführt. Sie sorgt dafür, dass der Treiber sauber beendet und der Appium-Dienst vollständig gestoppt wird. Das verhindert, dass Hintergrundprozesse offen bleiben oder der Server in einem blockierten Zustand endet.
Durch diese Struktur können alle anderen Testklassen einfach die Basisklasse erweitern. Damit erhalten sie Zugriff auf denselben Treiber, ohne ihn selbst neu konfigurieren zu müssen. Das ermöglicht es mir, in weiteren Testdateien direkt mit dem Gerät zu interagieren – beispielsweise Elemente auszuwählen, Aktionen zu simulieren oder App-Zustände auszulesen – ohne sich erneut um Verbindungen oder Setup kümmern zu müssen.
Insgesamt schafft diese zentrale Testbasis eine klare Trennung zwischen Einrichtung und eigentlicher Testlogik. Das spart Zeit, macht den Code übersichtlicher und sorgt für ein stabiles und reproduzierbares Testumfeld.
Für die eigentliche Interaktion mit mobilen Apps nutze ich eine Reihe von Appium-Funktionen und Werkzeugen, die es mir ermöglichen, ein breites Spektrum an Benutzeraktionen zu simulieren. Damit kann ich unter anderem typische Gesten wie Scrollen, Swipen oder längere Bildschirmberührungen nachbilden – Funktionen, die im Emulator genau so ausgeführt werden, wie ein Benutzer sie auf einem echten Gerät ausführen würde.
Der Appium Inspector spielt eine zentrale Rolle bei der Analyse von Oberflächenstrukturen. Er zeigt die Hierarchie der UI-Elemente und gibt Vorschläge für mögliche Locator-Strategien aus, etwa über IDs, XPaths oder andere Attribute. Diese Informationen nutze ich später im Testcode, um Elemente gezielt auszuwählen und mit ihnen zu interagieren.
Ein gefundenes Element kann ich anschließend über den Treiber ansprechen – der Treiber wird in meiner Basisklasse zentral definiert und steht allen Testklassen automatisch zur Verfügung. Dadurch kann ich in den Tests Elemente auswählen und typische Aktionen ausführen, zum Beispiel Klicks, das Auslesen von Text oder das Befüllen von Eingabefeldern. Textwerte lassen sich dann über Assertions vergleichen, um zu prüfen, ob die App die erwarteten Inhalte anzeigt.
Darüber hinaus kann ich vom System bereitgestellte Aktionen simulieren, etwa das Drücken der Android-Systemtasten über entsprechende Key Events oder das Drehen des Bildschirms über Rotationsbefehle. Solche Funktionen sind besonders hilfreich, wenn ich testen möchte, wie stabil eine App mit verschiedenen Eingaben oder Gerätezuständen umgeht.
Wenn Elemente ähnliche oder identische XPaths besitzen, kann ich zusätzliche Attribute nutzen, um das richtige Element zu unterscheiden – beispielsweise über bestimmte Textwerte oder andere Eigenschaften. In komplexeren Strukturen, in denen mehrere Elemente verschachtelt sind, kann ich über Schleifen durch übergeordnete Container iterieren und anhand spezifischer Attribute gezielt dasjenige Element auswählen, das ich benötige. So lässt sich der Umgang mit dynamischen Listen oder Produktkatalogen zuverlässig automatisieren.
Ein weiterer wichtiger Aspekt ist das Arbeiten mit expliziten oder impliziten Wartezeiten. Dadurch kann ich sicherstellen, dass ein bestimmtes Element erst dann weiterverarbeitet wird, wenn es auch tatsächlich sichtbar oder erreichbar ist. Das ist besonders nützlich, wenn Elemente zwar die gleiche ID besitzen, aber je nach Bildschirm oder App-Seite unterschiedlichen Inhalt haben.
Insgesamt ermöglichen mir diese Werkzeuge und Strategien, mit mobilen Apps ähnlich flexibel zu arbeiten, wie ein echter Benutzer es tun würde – nur reproduzierbar und automatisiert. Durch die Kombination aus Appium Inspector, geeigneten Locator-Strategien und den verschiedenen Interaktionsmöglichkeiten entsteht so ein belastbares Testframework, das auch komplexe App-Oberflächen sicher abdecken kann.
Beim Arbeiten mit Appium habe ich gelernt, dass mobile Apps grundsätzlich in zwei Kontexten ausgeführt werden können: dem nativen Kontext NATIVE_APP und dem WebView-Kontext WEBVIEW. Native Screens lassen sich direkt über Appium ansteuern, während WebViews eine Art eingebetteter Browser sind und daher spezielle Anforderungen haben.
Der Wechsel in einen WebView-Kontext funktioniert nur dann zuverlässig, wenn Appium einen ChromeDriver findet, der zur internen WebView- oder Chrome-Version des Geräts passt. Dabei ist entscheidend, dass die Major-Versionen übereinstimmen – sonst lässt sich keine Browser-Session aufbauen.
In der Praxis hängt es vom Webinhalt ab, welcher ChromeDriver benötigt wird, um die Inhalte zu laden:
- Wird die Chrome-App direkt im Emulator gestartet, muss der ChromeDriver zur installierten Chrome-App-Version passen.
- Wird innerhalb einer App ein WebView geöffnet, nutzt dieser häufig eine eigene WebView-Engine, die sich in der Version von Chrome unterscheiden kann. Dafür ist dann wiederum ein anderer ChromeDriver notwendig.
Dadurch kann WebView-Automatisierung fehleranfällig sein, besonders wenn Chrome oder WebView im Emulator nicht manuell aktualisiert werden können. Moderne Appium-Versionen bieten inzwischen die Möglichkeit, den passenden ChromeDriver automatisch herunterzuladen, was diese Probleme deutlich reduziert – insbesondere dann, wenn man im Emulator keinen Google-Account hinterlegen möchte und somit keinen Zugriff auf den Play Store hat.
Ohne automatischen Download bleibt oft nur der Weg über manuell installierte APKs. Viele aktuelle Chrome-Versionen benötigen jedoch zusätzliche Komponenten wie die Trichrome Library, was das Setup weiter erschwert.
Wenn ein WebView-Kontext kurzfristig nicht erreichbar ist – zum Beispiel bei einem Google-Popup, das keine nutzbaren UI-Elemente bereitstellt – kann man dennoch weiterarbeiten. In solchen Fällen setze ich pragmatische Workarounds ein, etwa Taps über Koordinaten oder das Senden von Key Events wie „Enter“, um Eingaben zu simulieren. Das ist funktional, auch wenn es nicht die Stabilität sauberer WebView-Automatisierung erreicht.
Durch diese Erfahrungen habe ich ein gutes Verständnis dafür entwickelt, woran WebView-Automatisierung scheitern kann und wie man dennoch testbar bleibt, wenn man vorübergehend auf native Workarounds ausweichen muss.
Projekt: Software-Testing mit Playwright & TypeScript
Der Einstieg in Playwright beginnt für mich mit JavaScript, da TypeScript technisch darauf aufbaut. In JavaScript können Variablen ihren Typ zur Laufzeit ändern, was sehr flexibel ist, aber auch zu unerwarteten Fehlern führen kann.
JavaScript kennt sowohl klassische String-Verkettung als auch moderne String-Interpolation:
var nachricht1 = "Der Preis für deine Ware " + wareX + " ist " + preisX + " Euro"; // Konkatenation (Verkettung)
var nachricht12 = `Der Preis für deine Ware ${wareX} ist ${preisX} Euro`; // Interpolation
Diese Interpolation mit Backticks (`) und ${} funktioniert
in JavaScript und TypeScript und erinnert mich stark an die f-Strings aus Python.
Im Vergleich zur klassischen Verkettung scheint sie deutlich lesbarer zu sein.
In JavaScript und TypeScript müssen Klassen, Funktionen oder Objekte explizit exportiert werden, wenn sie in anderen Dateien verwendet werden sollen:
export class LoginPage {
login() {
// Login-Logik
}
}
Der Import erfolgt anschließend in einer anderen Datei:
import { LoginPage } from "./someClasses.js";
Ohne dieses export / import-Prinzip existiert der Code nur
lokal in der jeweiligen Datei.
Der entscheidende Schritt von JavaScript zu TypeScript ist die Typensicherheit. TypeScript erweitert JavaScript um feste Typen, die bereits zur Entwicklungszeit überprüft werden:
var preisX: number = 10;
var wareX: string = "Apfel";
Einmal als number definiert, kann eine Variable nicht plötzlich
zu einem string werden. Dadurch werden viele typische Laufzeitfehler
bereits im Editor oder beim Build erkannt. Dieses Verhalten scheint Java zu ähneln
und TypeScript für größere Testprojekte geeignet zu machen.
Zusammengefasst stechen für mich die folgenden Besonderheiten hervor:
- wie JavaScript-Strings funktionieren und warum Interpolation besser lesbar sein kann,
- wie Module über
exportundimportaufgebaut sind, - und wie Typensicherheit helfen kann, stabilen und wartbaren Testcode zu schreiben.
Nachdem ich meine Umgebung in Visual Studio Code eingerichtet habe (inklusive Playwright-Erweiterung), kann ich Tests in TypeScript strukturiert schreiben und direkt aus der IDE oder über die Konsole ausführen.
In den meisten Testdateien importiere ich dafür test und häufig zusätzlich
expect aus dem Playwright-Testpaket:
import { test, expect } from '@playwright/test';
test liefert die Teststruktur und expect
stellt Assertions bereit, um Zustände zu prüfen.
Dadurch ist das Schreiben von Tests klar aufgebaut.
Für Web-Tests gibt es grundsätzlich zwei typische Startpunkte:
- Lokale Anwendung starten: Wenn ich ein Projekt lokal laufen lasse, passiert das oft über
npm start(Eingabe in der Konsole von VS Code). Dadurch läuft die App z.B. unter einem lokalen Port (häufig etwas wiehttp://localhost:4200). Dieser Vorgang (npm start) muss jedes Mal erfolgen, damit die Anwendung unter dem lokalen Port erreichbar ist, bevor sie automatisiert getestet werden kann. - Direkt eine URL testen: Alternativ kann ich auch ohne lokalen Server eine Webseite direkt ansteuern,
indem ich im Test mit
page.goto()navigiere.
Ein typischer Einstieg im Test sieht dann so aus:
import { test, expect } from '@playwright/test';
test('Titel ist korrekt', async ({ page }) => {
await page.goto('http://localhost:4200');
await expect(page).toHaveTitle(/Playwright/);
});
Die Ausführung der Tests ist flexibel. Ich kann sie direkt über VS Code starten, oder über die Konsole. Besonders praktisch finde ich den UI-Modus von Playwright, weil ich dabei Schritt für Schritt sehen kann, was der Test tut:
npx playwright test --ui
Neben dem normalen Ausführen bietet Playwright auch nützliche Steuerungsmöglichkeiten, um Tests gezielt ein- oder auszuschließen. Das ist hilfreich, wenn ich gerade an einem einzelnen Test arbeite oder bestimmte Fälle vorübergehend deaktivieren will:
test.skip(...)– überspringt einen Test bewusst (z.B. wegen Bug oder fehlender Funktion).test.only(...)– führt nur diesen Test aus, um fokussiert zu debuggen.
import { test, expect } from '@playwright/test';
test.skip('Feature ist noch in Arbeit', async ({ page }) => {
// wird aktuell nicht ausgeführt
});
test.only('Fokustest zum Debuggen', async ({ page }) => {
await page.goto('https://example.com');
await expect(page).toHaveTitle(/Example/);
});
Zusammengefasst lerne ich in diesem Abschnitt vor allem:
- wie Playwright-Tests über
import { test, expect }aufgebaut sind, - wie ich eine App lokal starte (z.B.
npm start) und über Ports im Browser erreiche, - wie Navigation im Test mit
await page.goto()funktioniert, - und wie ich Tests über VS Code oder über
npx playwright test --uiausführen kann.
Ein zentraler Bestandteil der Arbeit mit Playwright ist das zuverlässige Finden
und Ansprechen von UI-Elementen. Dafür stellt Playwright die Methode
page.locator() bereit.
Elemente können dabei auf unterschiedliche Weise lokalisiert werden – unter anderem
über IDs, Klassen oder spezifische Attribute wie placeholder,
oder andere HTML-Eigenschaften:
const usernameInput = page.locator('#username');
const passwordInput = page.locator('.password-field');
const searchField = page.locator('input[placeholder="Search"]');
Im Vergleich zu Selenium wird XPath in Playwright anscheinend eher selten genutzt. Obwohl XPath weiterhin unterstützt wird, liegt der Fokus wohl auf stabileren und besser lesbaren Selektoren wie CSS-Selektoren. Dadurch sollen Tests robuster gegenüber UI-Änderungen sein.
Ein weiterer wichtiger Aspekt sind Timeouts. Playwright arbeitet mit impliziten Wartezeiten, die je nach Aktion variieren. Viele Befehle warten automatisch, bis ein Element sichtbar, anklickbar oder verfügbar ist.
Zusätzlich kann in der zentralen Konfigurationsdatei ein globales Timeout definiert werden, das für alle Tests gilt. Je nach verwendeter Funktion existieren jedoch unterschiedliche Timeout-Fenster, sodass nicht jede Aktion exakt gleich lange wartet.
Bei Bedarf lassen sich Timeouts auch direkt im Testcode überschreiben – gezielt für einzelne Aktionen:
await expect(startButton).toHaveText('Beginne hier', {timeout: 20000})
Wenn Elemente hierarchisch aufgebaut sind, können Locators miteinander verkettet werden. Dabei wird von einem übergeordneten Element zu dessen Childelementen navigiert. Dieses Vorgehen ist besonders hilfreich bei Listen, Formularen oder komplexen Containern:
Existieren mehrere Elemente, auf die ein Locator zutrifft, bietet Playwright verschiedene Filtermöglichkeiten. So lassen sich Elemente gezielt anhand ihres Textinhalts oder ihrer Rolle (z.B. Button oder Textbox) auswählen:
await page.locator('button', { hasText: 'Login' }).click();
await page.getByRole('textbox', { name: 'Email' }).fill('test@example.com');
Das Befüllen von Eingabefeldern sowie das Auslesen von Werten ist ebenso möglich. Diese Werte lassen sich anschließend mit Assertions überprüfen, um das erwartete Verhalten der Anwendung sicherzustellen:
await page.locator('#username').fill('guest');
const welcomeText = page.locator('.welcome-message');
await expect(welcomeText).toHaveText('Welcome guest');
Durch eine Kombination aus stabilen Locator-Strategien, automatischem Warten, angepassten Timeouts und aussagekräftigen Assertions können sich UI-Tests schreiben lassen, die sowohl robust als auch gut wartbar erscheinen.
Zusammengefasst lerne ich in diesem Abschnitt vor allem:
- wie Elemente mit
page.locator()zuverlässig gefunden werden, - warum XPath in Playwright seltener eingesetzt wird als in Selenium,
- dass globale und lokale Timeouts zusammenspielen,
- wie sich Locator verketten und filtern lassen,
- und wie Eingaben und Assertions zur Validierung von Testergebnissen genutzt werden.
Projekt: Datenanalyse mit Power BI
Bevor ich mit einer technischen Datenanalyse beginne, halte ich es für wichtig zu verstehen, was Daten überhaupt aussagen – und was sie verschweigen können. Deshalb starte ich mit zwei Fallbeispielen, die zeigen, warum Interpretation und Kontext oft entscheidender sind als reine Zahlen.
Im Anschluss folgt ein praktisches Beispiel in Power BI, bei dem ich einen Datensatz analysiere.
So entsteht eine Verbindung zwischen Datenverständnis und Datenpraxis – vom kritischen Denken bis hin zum konkreten Dashboard.
Ein spekulativer Hedgefonds beauftragt einen Datenanalysten, in einer bestimmten NFT-Kollektion seltene Kategorien zu identifizieren, deren Aufpreis sich am stärksten entwickeln könnte. Was auf den ersten Blick einfach klingt – „Finde die besten Kategorien“ – erfordert in der Praxis eine vielschichtige Analyse, bei der Fehlinterpretationen schnell teuer werden können.
Erste Herausforderung:
NFTs werden üblicherweise in Ether (ETH) gehandelt.
Selbst wenn der Verkaufspreis in ETH steigt, kann der tatsächliche Wert in US-Dollar sinken,
wenn der Kurs von Ether fällt.
Ohne eine konstante Umrechnung in eine Bezugswährung entstehen leicht Fehlschlüsse
über die tatsächliche Wertentwicklung.
Zweite Herausforderung:
Um Trends richtig zu erkennen, braucht der Analyst einen Referenzpunkt.
Nur der Vergleich von realisierten Verkäufen seltener Kategorien mit den niedrigsten realisierten Preisen
derselben Kollektion erlaubt Rückschlüsse auf reale Aufpreise – und damit auf die tatsächliche
Zahlungsbereitschaft des Marktes.
Dritte Herausforderung:
Viele Datenquellen enthalten sogenannte Listings – also Verkaufsangebote, keine realisierten Verkäufe.
Ein bestehender Angebotspreis zeigt lediglich, zu welchem Preis niemand kaufen wollte.
Für valide Trendanalysen sind deshalb ausschließlich tatsächliche Transaktionen relevant.
Dieses Beispiel zeigt, wie entscheidend es ist, bereits bei der Auswahl und Übersetzung von Rohdaten kritisch vorzugehen, bevor die eigentliche Analyse beginnt.
Ein Unternehmen möchte die Effektivität seiner Kommunikations- und Imageabteilung messen. Dafür verknüpft die Geschäftsführung Bonuszahlungen mit Kennzahlen wie der Weiterempfehlungsrate und der durchschnittlichen Bewertung auf Kununu. Steigen diese Werte, werden Boni ausgeschüttet – sinken sie, folgen Maßnahmen.
Auf den ersten Blick scheint das eine klare, datenbasierte Entscheidung: Mehr positive Bewertungen = bessere Außenwirkung = bessere Leistung der Abteilung. Doch genau hier beginnt die Bedeutung von Interpretation und Kontextbewusstsein.
Was, wenn die Abteilung bspw. nach kritischen Bewertungen selbst eingreift – etwa indem andere Mitarbeitende zu positiven Bewertungen angeregt werden oder Mitarbeiter der Kommunikations- und Imageabteilung nach sechs Monaten erneut eigene Einschätzungen veröffentlichen, um das Gesamtbild zu verbessern (da Kununu Mehrfachbewertungen nach dieser Frist erlaubt)?
Ein aufmerksamer Analyst könnte solche Muster erkennen:
- Auffällige Zunahme der Bewertungsfrequenz direkt nach negativen Kommentaren
- Cluster ähnlicher Bewertungen aus bestimmten Abteilungen oder mit wiederkehrender Wortwahl
- Häufung positiver Bewertungen aus einer Abteilung mit hoher Personalfluktuation
- Wiederholte Bewertungen derselben Nutzer nach Ablauf der 6-Monats-Frist
- Überproportional viele positive Bewertungen aus anderen Abteilungen als jener mit einer kritischen Bewertung
Eine einfache Visualisierung könnte helfen, solche Muster sichtbar zu machen – etwa eine Zeitachse mit allen Bewertungen (X: Zeit, Y: Sternebewertung), ergänzt durch Markierungen für Abteilung und Wiederholungsbewertungen.
So ließe sich indizieren, ob positive Bewertungswellen organisch entstehen oder gezielt induziert wurden. Wichtig dabei: Wenn solche Auswertungsmethoden intern bekannt werden, könnten sich neue, schwerer erkennbare Manipulationsmuster entwickeln – ein gutes Beispiel dafür, wie Analyse und Beobachtung selbst Mechanismen verändern können.
In der Datenanalyse ist es wichtig, nicht nur Muster zu erkennen, sondern auch Ausnahmen richtig einzuordnen. Denn bestimmte Ereignisse oder Zeiträume können Ergebnisse stark verzerren, wenn sie ohne Kontext betrachtet werden.
Ein typisches Beispiel sind Sonderaktionen wie der Black Friday. Steigt der Umsatz in dieser Zeit stark an, bedeutet das nicht zwingend ein nachhaltiges Wachstum – häufig folgt darauf ein Umsatzeinbruch, weil viele Kundinnen und Kunden ihre geplanten Käufe vorgezogen haben. Um solche Effekte realistisch zu bewerten, sollten Black-Friday-Daten daher nur mit Aktionen aus vergleichbaren Zeiträumen anderer Jahre verglichen werden.
Weitere Einflüsse können einmalige oder wiederkehrende Ereignisse sein, wie z. B.:
- Steueranpassungen – etwa Änderungen der Mehrwertsteuer, die kurzfristig zu Rabattaktionen führen können.
- Jubiläumsaktionen – jährliche Sonderrabatte, die alle zehn Jahre besonders stark ausfallen.
- Datenlücken – z. B. durch Systemausfälle oder fehlende Erfassungen in bestimmten Zeiträumen.
Solche Sondersituationen zeigen, dass Daten ohne Kontext nur die halbe Wahrheit erzählen. Wer Trends analysiert, sollte daher immer prüfen, ob ein auffälliger Ausschlag tatsächlich ein Marktsignal ist – oder schlicht eine Ausnahme.
Im nächsten Schritt möchte ich zeigen, wie aus einem Rohdatensatz ein auswertbares Analyseprojekt entsteht. Dafür habe ich auf einer öffentlichen Datenplattform (Kaggle) einen passenden Datensatz im .csv-Format heruntergeladen und mit einer kurzen Python-Datei in eine SQLite-Datenbank (.db) umgewandelt.
Die Verarbeitung erfolgte in einem PyCharm-Projekt, in dem eine virtuelle Umgebung (.venv)
genutzt wurde. Darin habe ich die benötigten Pakete – pandas und
sqlite3 – aktiviert.
Dieses Vorgehen folgt dem klassischen ETL-Prinzip der Datenanalyse:
- Extract (Extrahieren): Der Datensatz wird aus der Quelle geladen (z. B. CSV-Datei oder API).
- Transform (Transformieren): Die Daten werden bereinigt, vereinheitlicht und mit neuen Kennzahlen ergänzt (z. B. Gewinnmargen, Datumsformate).
- Load (Laden): Die bereinigten Daten werden in eine SQLite-Datenbank geschrieben, um sie später in Power BI oder SQL weiter auszuwerten.
Damit ist die technische Grundlage gelegt – im nächsten Abschnitt folgt die Auswertung der .db-Datei und die Visualisierung der Ergebnisse in Power BI.
Für das Analyseprojekt verwende ich das öffentlich verfügbare Superstore Dataset von Kaggle. Es stammt ursprünglich aus einer Beispielanalyse auf der Tableau-Website und wird häufig zu Lernzwecken eingesetzt.
Das fiktive Unternehmen „Superstore“ ist ein großer Einzelhändler, der Produkte aus verschiedenen Kategorien wie Technik, Möbel und Bürobedarf verkauft. Ziel der Analyse ist es, herauszufinden, welche Produkte, Produktkategorien, Regionen, oder Kundensegmente besonders profitabel sind.
Der Datensatz enthält typische Geschäftsdaten, darunter:
- Kundendaten: Customer ID, Customer Name, Segment, Region
- Produktdaten: Kategorie, Unterkategorie, Product Name, Product ID
- Bestelldaten: Order ID, Order Date, Sales, Profit, Discount
- Versanddaten: Ship Date, Ship Mode
Eine naheliegende erste Fragestellung in der Datenanalyse lautet: Welche Produkte sind am profitabelsten? Zur Beantwortung wurde die aggregierte Summe des Profits pro Produkt visualisiert und eine Tabelle mit SQL erstellt, welche auch die Ober- und Unterkategorie der profitabelsten Produkte anzeigt.
Das erste Diagramm zeigt eine klare Konzentration auf wenige hochprofitable Produkte – die meisten Artikel erzielen dagegen nur geringe oder sogar marginale Gewinne. Wie die zweite Abbildung verdeutlicht, zählt kein Produkt der Oberkategorie „Furniture“ zu den 25 profitabelsten Artikeln.
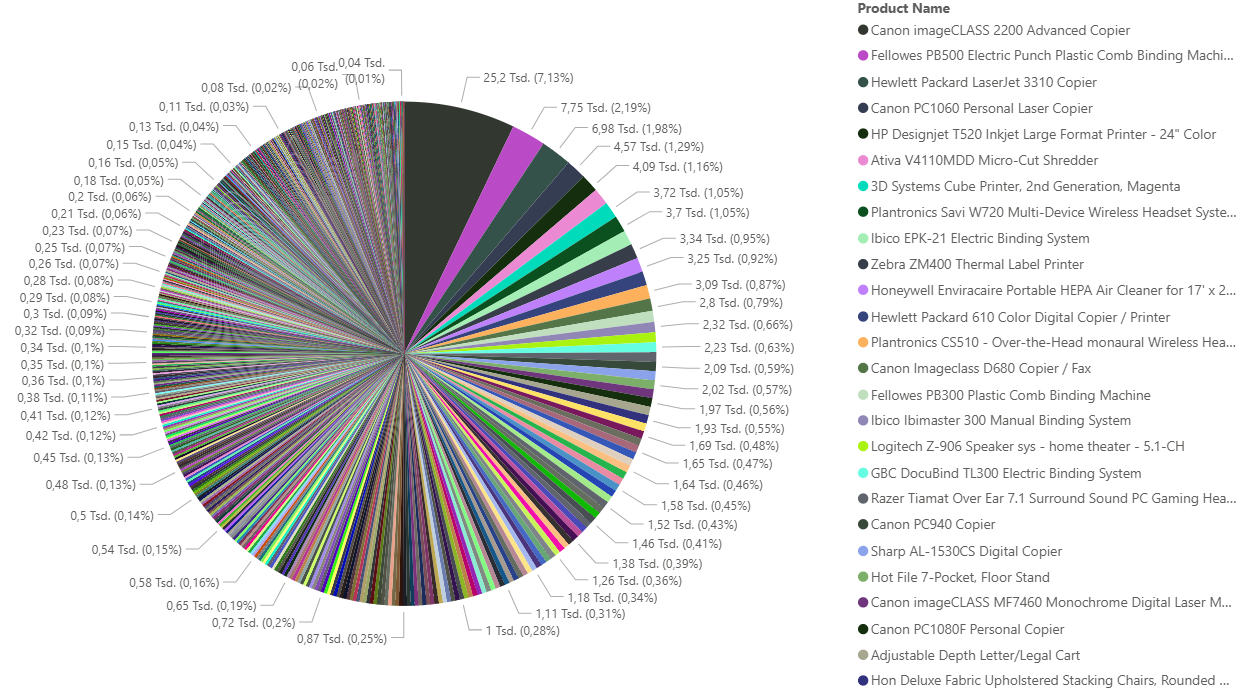
Abb. 1: Profitverteilung nach Produktname

Abb. 2: Produkttabelle sortiert nach Profit
Diese Auswertung beantwortet eine einfache, aber wichtige Einstiegsfrage (welche Produkte am profitabelsten sind). Noch spannender wird es, wenn wir uns im nächsten Schritt ansehen, welche Produktkategorien besonders profitabel oder verlustreich sind.
Nach der Betrachtung einzelner Produkte folgt eine Auswertung auf Ebene der Unterkategorien. Die folgenden Diagramme zeigen die aggregierten Werte für Profit, Profit-Marge, Rabatt und Sales (Umsatz) pro Sub-Category.
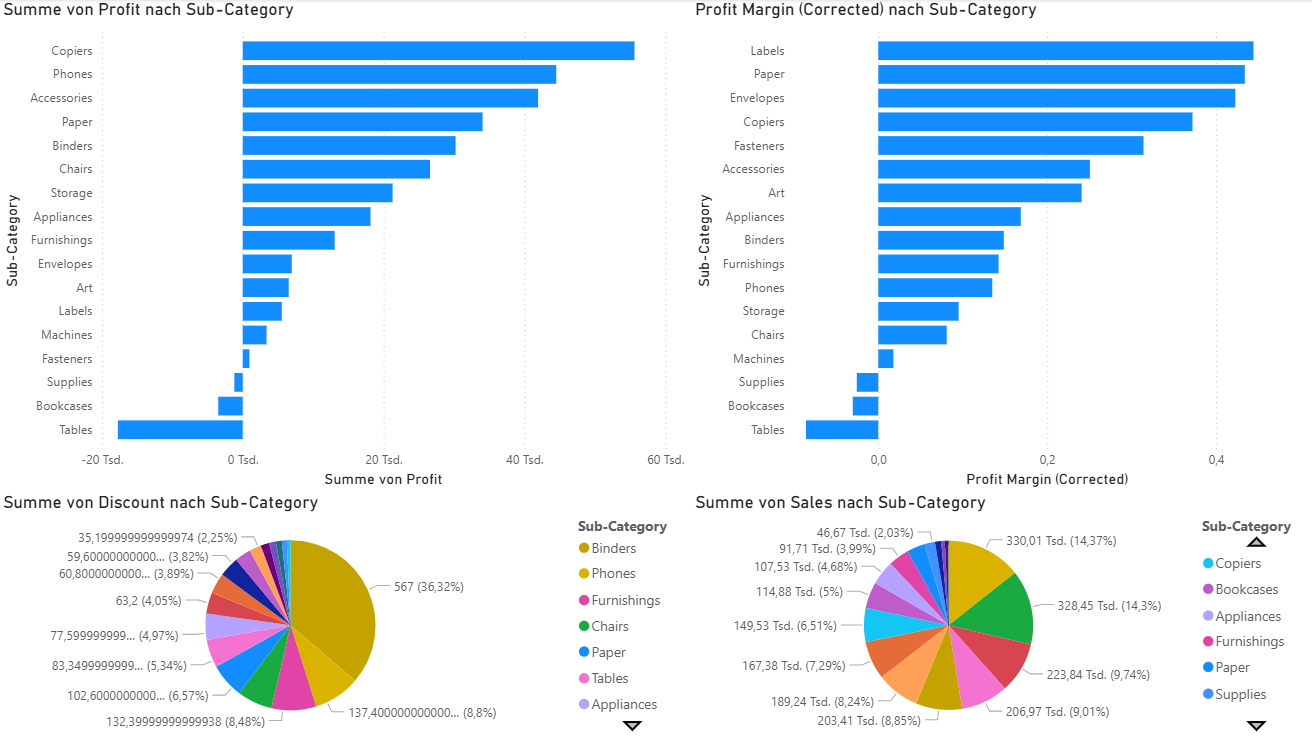
Abb. 3: Mehrdimensionale Analyse der Unterkategorien
Besonders auffällig ist die Kategorie Copiers (Drucker). Sie erzielt den höchsten Gesamtprofit, was durch eine Kombination aus relativ hoher Profit-Margin und moderatem Umsatz (6,51%) erklärt werden kann.
Interessant ist außerdem die Unterkategorie Labels: Sie weist die höchste Profit-Marge auf, erzielt im Verhältnis dazu aber nur einen geringen absoluten Gesamtprofit – was sich durch den geringen Umsatz (0,54%) erklären lässt.
Bei den Discounts fällt die Kategorie Binders auf. Sie hat einen hohen Umsatz (8,85%) und eine moderate Profit-Margin, was sich in einem guten absoluten Profit niederschlägt, obwohl die Kategorie die höchsten Discounts aufweist.
In der Umsatzbetrachtung liegen Phones (Telefone) vorn – mit dem zweithöchsten Anteil an Rabatten. Trotz der nur moderaten Profit-Margin führt der höchste Umsatz (14,37%) zu dem zweithöchsten absoluten Gesamtprofit.
Die Kategorien Supplies, Bookcases und Tables verzeichnen alle absolute Verluste sowie negative Profit-Margins. Tables haben dabei einen hohen Umsatz (9,01%) und nehmen zudem 5,34% der Discounts ein. Supplies haben einen Umsatz von 2,03% und nehmen 0,94% der Discounts ein. Bookcases weisen einen Umsatz von 5% auf und nehmen 3,08% der Discounts ein.
Bei diesen 3 Produktkategorien stellt sich die Frage, ob Sie entweder aus dem Sortiment gestrichen werden sollte, angepasst (durch das Streichen der unprofitablen Produkte) oder im Sortiment behalten werden sollten, da Käufer bspw. den Superstore wegen dieser Produkte aufsuchen und dann viele weitere Produkte erwerben, was insgesamt profitabel für die Bilanz ist. Denn auch eine umfangreiche Auswahl kann Kunden anziehen.
Insgesamt zeigt diese Analyse, dass sich die Profitabilität einer Unterkategorie nicht allein aus Umsatz oder Marge ergibt, sondern aus ihrem Zusammenspiel, und weitere Faktoren wie das Kaufen weiterer Produkte nach dem Erwerb des initial gewünschten Produktes nicht durch die Grafiken abgebildet werden.
Auch wenn eine gesamte Sub-Category (wie hier Tables) in der Summe Verluste einfährt,
lohnt sich ein Blick auf die Einzelebene der Produkte.
In Power BI kann dazu ein Balkendiagramm erstellt werden,
das nach Product Name gruppiert und mit einem Filter auf die gewünschte Sub-Category eingeschränkt wird.
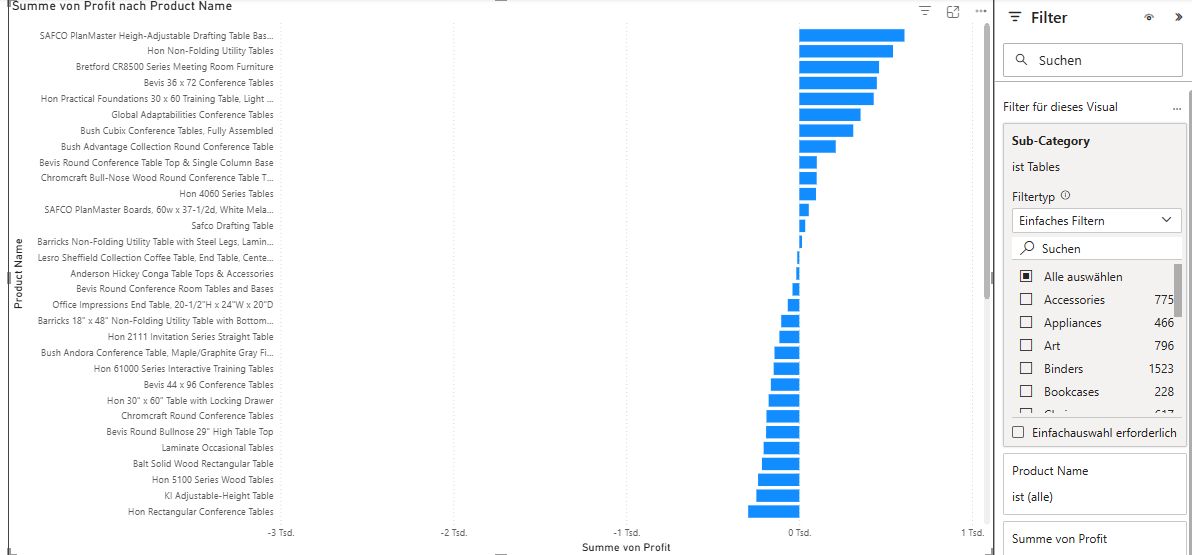
Abb. 4: Produktbezogene Profitanalyse innerhalb der Sub-Category „Tables“
In dieser Ansicht wird sichtbar, dass einzelne Tischmodelle durchaus profitabel sind, auch wenn die Sub-Category insgesamt Verluste verzeichnet. Solche Produkte können strategisch wichtig sein – etwa, weil sie besonders stabil im Absatz sind oder regelmäßig ohne Rabatte verkauft werden.
Diese Detailanalyse zeigt, wie wichtig es ist, aggregierte Werte zu hinterfragen und bei Bedarf in die Produkt-Ebene zu „drillen“. Nur so lassen sich echte Ausreißer und versteckte Erfolgsprodukte identifizieren, die im Gesamtergebnis sonst untergehen würden.
In Power BI gelingt diese Art der Untersuchung ganz einfach über den rechten Seitenbereich:
- Visualisierung: Balkendiagramm mit
Product Nameauf der Y-Achse undProfitauf der X-Achse - Filter: Sub-Category = Tables
🧠 Interpretation & strategische Bedeutung
Für datengetriebene Entscheidungen ist es entscheidend, Verluste und Gewinne granular zu betrachten – auf Ebene einzelner Produkte, Regionen oder Zeiträume. Nur so lassen sich gezielt Maßnahmen ableiten, z. B.:
- Beibehaltung oder Ausbau besonders profitabler Produkte
- Überprüfung von Rabattstrategien bei verlustreichen Artikeln
- Gezielte Sortimentsanpassungen nach Kundensegmenten oder Regionen
Damit wird die Analyse zur operativen Grundlage für Preisgestaltung, Marketing und Einkauf – und unterstützt strategische Entscheidungen auf Basis belastbarer Daten.
In diesem Abschnitt werden die erzielten Profite und Profit-Margen nach Regionen sowie Kundensegmenten dargestellt. Die Abbildungen zeigen deutlich, dass sich in den Regionen West und East die höchsten Werte sowohl beim absoluten Profit als auch bei der Profit-Marge realisieren lassen.
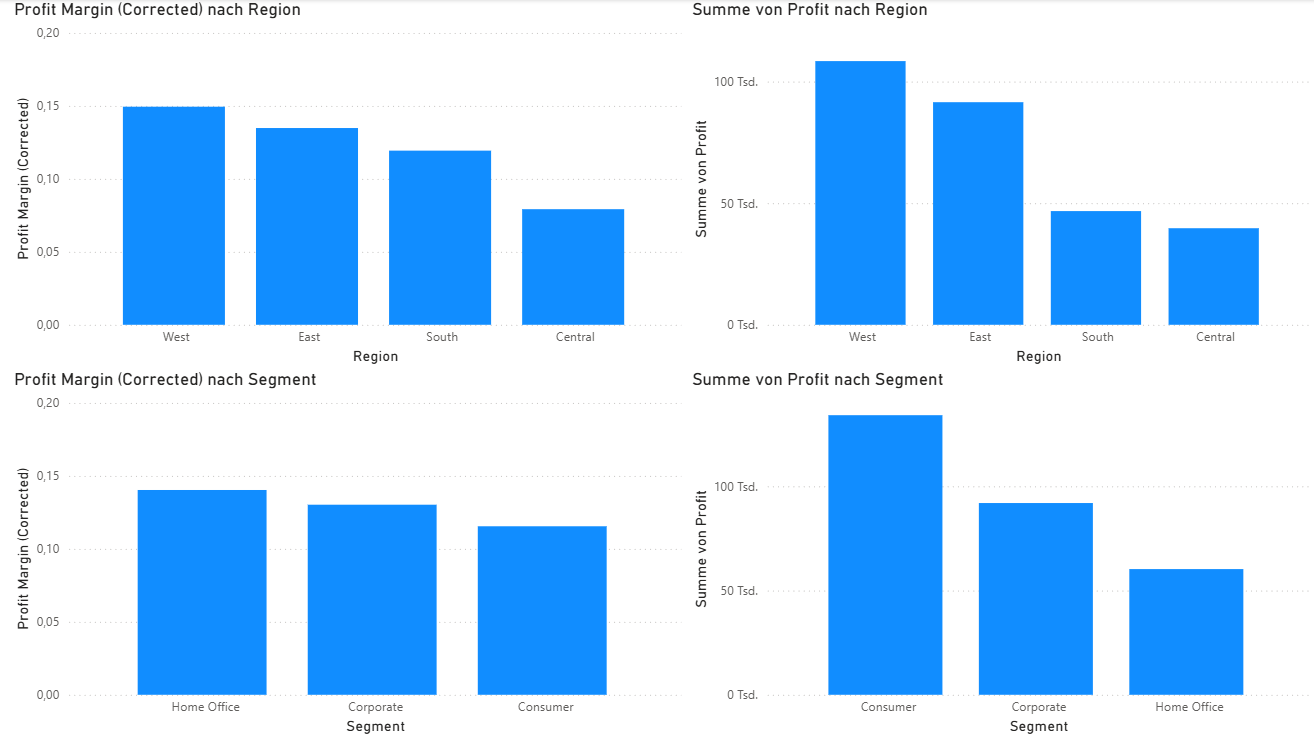
Abb. 5: Profit und Profit-Marge nach Region und Segment
Wenn man den Superstore als ein Unternehmen mit mehreren Filialen betrachtet, lässt sich daraus ableiten, dass Expansionsmaßnahmen am ehesten in diesen profitstarken Regionen sinnvoll erscheinen. Hier scheinen Nachfrage, Preisgestaltung oder Produktmix besonders gut zu harmonieren.
Betrachtet man die Kundensegmente, fällt auf, dass das Segment Home Office die höchste durchschnittliche Profit-Marge erzielt. Dennoch stammt der größte Anteil am Gesamtprofit aus dem Segment Consumer (Endkundenmarkt).
Dieses Ergebnis legt nahe, dass eine tiefergehende Analyse sinnvoll wäre – etwa zu folgenden Fragen:
- Können im Consumersegment durch bestimmte Aktionen höhere Profit-Margen bei nicht zu stark abfallenden Verkäufen realisiert werden?
- Fehlen im Corporate- oder Home-Office-Bereich möglicherweise weitere spezifische Produkte?
- Wie unterscheiden sich Kaufverhalten, Rabatte oder Produktpräferenzen zwischen den Segmenten?
Solche weiterführenden Analysen könnten helfen, die Sortimentsstrategie gezielt zu optimieren – und die Profitabilität langfristig zu steigern.
📊 Interpretation & strategische Bedeutung
Während die Regionen West und East klar die profitabelsten Standorte darstellen, zeigt sich, dass die höchste Profitabilität pro verkauftem Produkt im Segment Home Office liegt – aber der größte Gewinnanteil durch die Vielzahl der Verkäufe an Consumer-Kunden entsteht.
Strategisch könnte dies bedeuten: Consumer bietet aktuell den besten Return durch Volumen, während Home Office durch eine gesteigerte Produktauswahl oder Premiumangebote weiter ausgebaut werden könnte. Die Kombination beider Erkenntnisse kann helfen, Marketing und Sortiment noch präziser auszurichten.
Um die Entwicklung von Profit, Umsatz und Marge im Zeitverlauf zu analysieren, wurden die Daten sowohl in Power BI als auch mit direkter SQL-Abfrage in der SQLite-Datenbank untersucht. Zum Öffnen und Abfragen der Datenbank wurde das kostenlose Tool DB Browser for SQLite verwendet.
Die folgende Grafik zeigt die jährliche Entwicklung von Gesamtumsatz und Gesamtprofit im Superstore-Datensatz. Zu sehen ist ein stetiger Anstieg beider Werte zwischen 2014 und 2017 – mit deutlicher Zunahme der Verkaufsaktivität und stabil wachsenden Gewinnen.
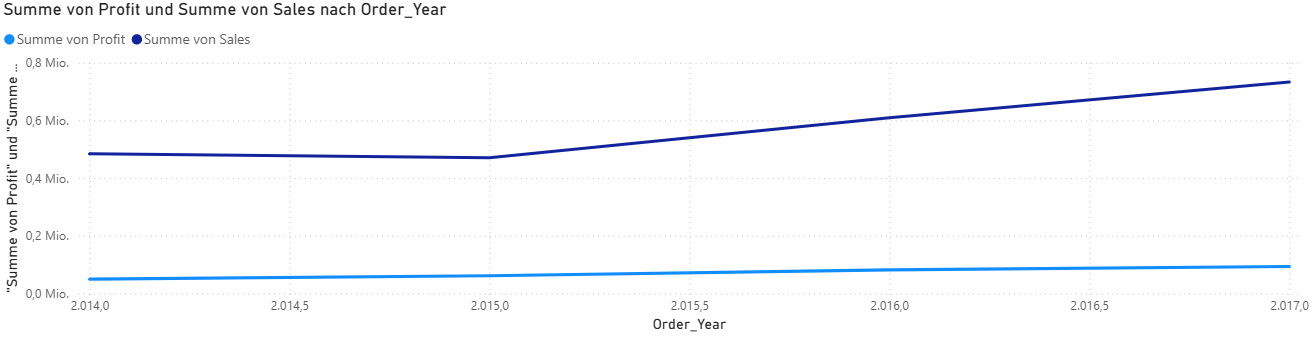
Abb. 6: Entwicklung von Profit und Sales pro Jahr (Power BI)
Für eine detailliertere Betrachtung wurden die Daten anschließend per SQL-Abfrage nach Jahr und Monat gruppiert. Damit lassen sich monatliche Schwankungen und Ausreißer präzise nachvollziehen:
SELECT
strftime('%Y', "Order Date") AS Jahr,
strftime('%m', "Order Date") AS Monat,
ROUND(SUM(Profit), 2) AS Gesamt_Profit,
ROUND(SUM(Sales), 2) AS Gesamt_Umsatz,
ROUND(SUM(Profit) / SUM(Sales), 3) AS Profit_Marge
FROM sales
GROUP BY Jahr, Monat
ORDER BY Jahr DESC, Monat ASC;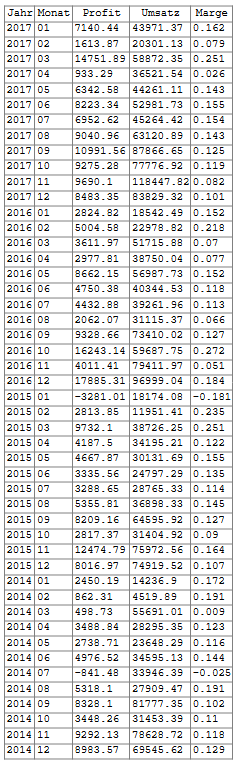
Abb. 7: Monatsweise aggregierte Werte (DB Browser / SQLite)
Diese tabellarische Analyse ergänzt die Power BI-Grafik sinnvoll: Während der Gesamttrend im Jahresverlauf klar auf Wachstum hindeutet, zeigt die SQL-Tabelle starke monatliche Schwankungen. Einzelne Monate mit negativen Margen (z. B. Januar 2015 oder Juli 2014) deuten auf mögliche Rabattaktionen oder Lagerabverkäufe hin. Die Prüfung dieser Hypothese wäre u. a. mit dem Attribut Discount in Power BI möglich.
Ein klares Muster lässt sich hingegen nicht klar erkennen, wenn man nur auf die Monatsebene schaut. Sobald man sich aber die Quartale anschaut, kann man erkennen, dass bspw. der Umsatz jedes Jahr vom ersten bis zum vierten Quartal steigt.
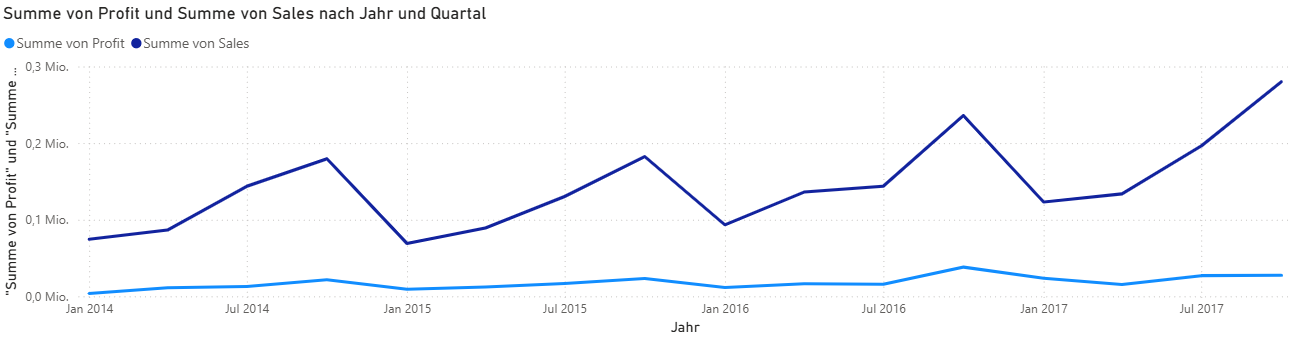
Abb. 8: Umsatz und Profit nach Quartalen
📈 Interpretation & strategische Bedeutung
Die Kombination aus SQL-Tabellenanalyse und Power BI-Visualisierung zeigt, dass Profit und Umsatz stetig (pro Jahr) wachsen, und Marge, Profit und Umsatz auf Monatsebene teils stark variieren.
Eine weiterführende Analyse könnte untersuchen, ob bestimmte Monate dauerhaft über- oder unterdurchschnittlich performen. So lassen sich strategische Verkaufsfenster identifizieren.
Während Power BI hervorragende Möglichkeiten zur Visualisierung bietet, stößt es bei komplexeren Fragestellungen oft an seine Grenzen. SQL ermöglicht hier eine präzisere und individuellere Analyse, bei der mehrere Filter, Kennzahlen und Sortierungen gleichzeitig berücksichtigt werden können.
Ein Beispiel ist die Analyse der Sub-Categories mit gleichzeitiger Betrachtung von Rabatt und Profit-Marge. In Power BI müssten dafür meist mehrere Visuals kombiniert werden. In SQL lässt sich beides in einer kompakten Tabelle darstellen, die nach Profit-Marge sortiert ist und dabei den durchschnittlichen Rabatt berücksichtigt.
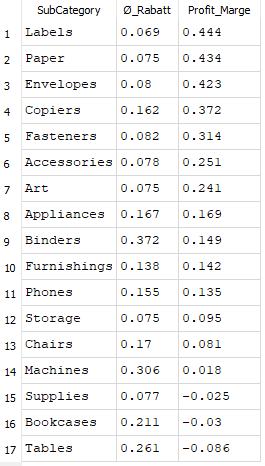
Abb. 9: Durchschnittlicher Rabatt und Profit-Marge je Sub-Category
Hier zeigt sich: Kategorien wie Labels und Paper weisen trotz moderater Rabatte die höchsten Profit-Margen auf. Dagegen fallen Tables und Bookcases durch negative Margen auf, was bspw. auf übermäßige Preisnachlässe oder hohe Einkaufskosten hindeutet.
Darüber hinaus lassen sich mit SQL auch gezielt Kunden mit hohem Profitbeitrag identifizieren. Statt lediglich den Umsatz zu betrachten, ist es strategisch sinnvoller, den tatsächlichen Gewinn pro Kunde zu fokussieren. Denn umsatzstarke Kunden können sogar unprofitabel sein, wenn sie bevorzugt rabattierte Produkte erwerben.
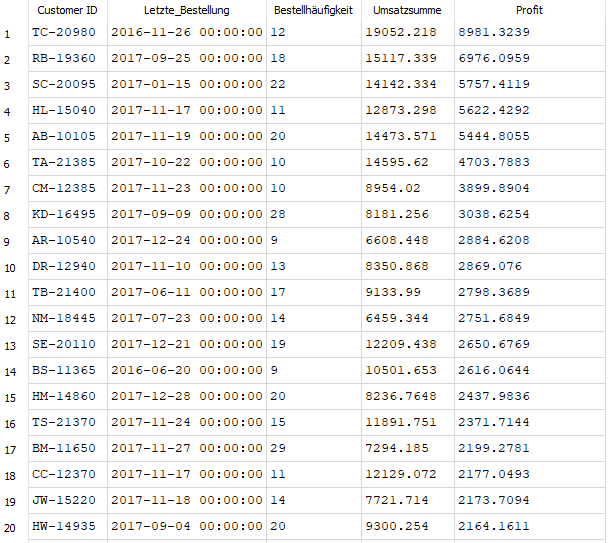
Abb. 10: Übersicht der profitabelsten Kunden nach Bestellhäufigkeit, Umsatz und Profit
Diese Sichtweise ermöglicht ein gezielteres Kundenmanagement: Welche Kund*innen tragen nachhaltig zum Gewinn bei. Die Kombination von Bestellhäufigkeit und Gesamtprofit schafft hier eine datenbasierte Entscheidungsgrundlage.
Ein weiteres Anwendungsbeispiel sind sogenannte Hidden Champions: Produkte mit einer überdurchschnittlich hohen Marge, deren Absatz jedoch bislang gering ist. Solche Artikel lassen sich mit SQL leicht identifizieren, um gezielte Maßnahmen zur Absatzsteigerung zu planen.
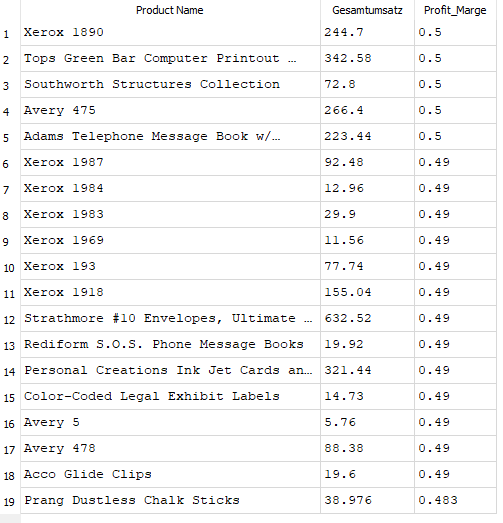
Abb. 11: Produkte mit hoher Profit-Marge und geringem Gesamtumsatz
Diese Analyse legt Potenziale offen, etwa für kurzfristige Rabattaktionen oder Marketingkampagnen, um Produkte mit starker Marge gezielt zu fördern. Im Gegensatz zu Power BI kann SQL hier sehr präzise Filterbedingungen kombinieren und so „unentdeckte“ Produktchancen sichtbar machen.
Prognosen mit Python oder R
Aufbauend auf den gewonnenen Kennzahlen lassen sich mit Programmiersprachen wie Python oder R Prognosen für Umsatz und Gewinn der nächsten Jahre erstellen. Dabei kommen statistische Modelle oder auch moderne Verfahren wie Prophet zum Einsatz.
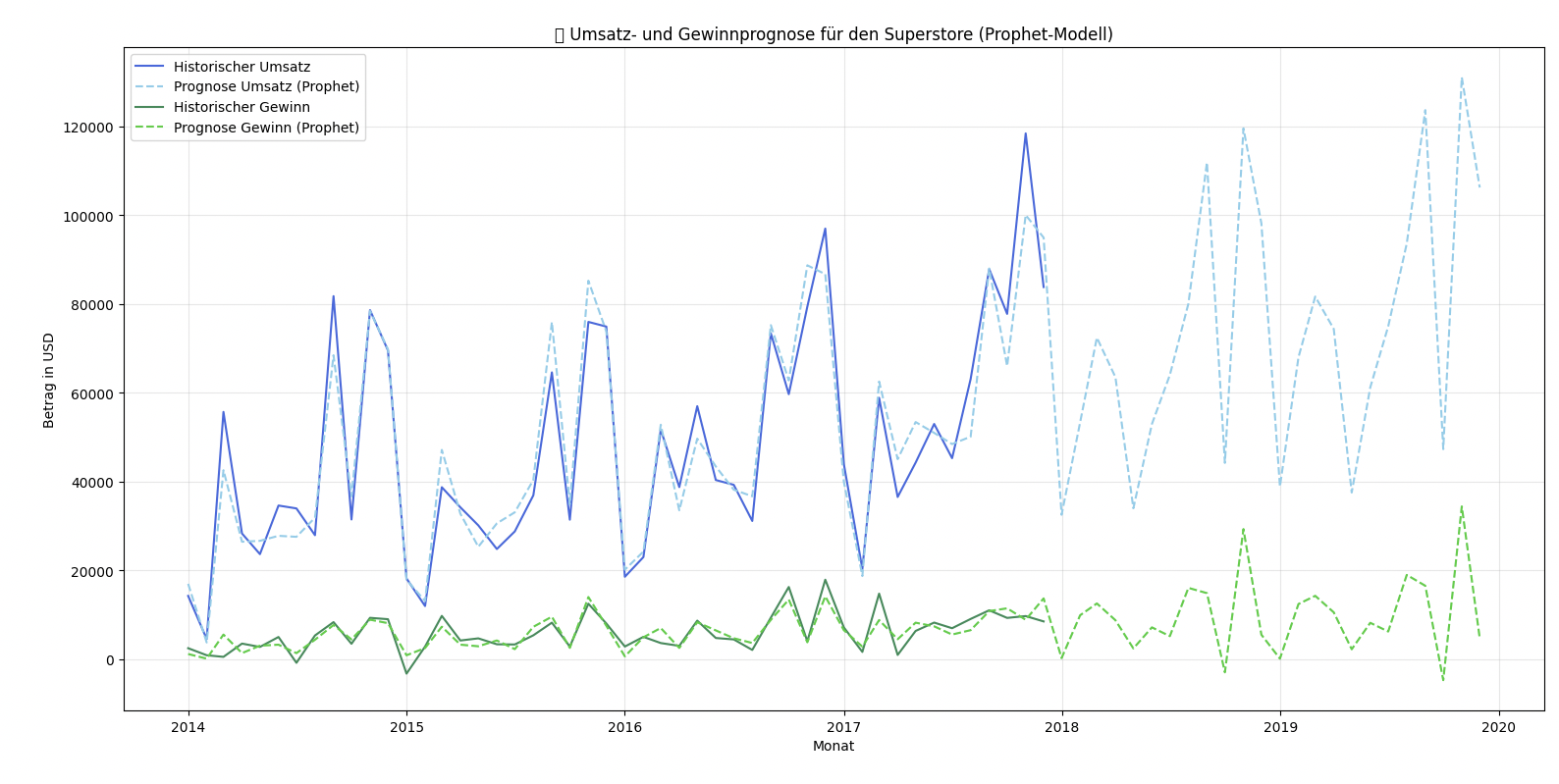
Abb. 12: Umsatz- und Gewinnprognose für den Superstore (Prophet-Modell, Python)
Solche Prognosen helfen, Trends frühzeitig zu erkennen und Entscheidungen in Einkauf und Marketing besser zu planen. Dennoch sollten sie als Zielmarken verstanden werden: Strategische Maßnahmen wie Sortimentsänderungen, Preis- und Rabattpolitik oder Filialeröffnungen können die zukünftige Entwicklung erheblich beeinflussen.
Prognosen basieren auf Vergangenheitsdaten – sie zeigen also, wie sich die Zahlen unter gleichbleibenden Rahmenbedingungen entwickeln würden. Externe Faktoren wie Marktsättigung (z. B. bei Druckern), neue Wettbewerber oder technologische Veränderungen können die tatsächliche Entwicklung jedoch deutlich abweichen lassen.
Daher sollten Prognosen nie als unverrückbare Vorhersage, sondern als datenbasierte Orientierung verstanden werden, die in Kombination mit Marktwissen, Kundenfeedback und Unternehmensstrategie interpretiert werden muss.
PyCharm-Projekt die erforderlichen Python-Pakete installiert
(pandas, matplotlib, statsmodels, prophet etc.) und einen vorgefertigten Code einmal durchlaufen lassen,
der automatisch diese Vorhersage erzeugt hat.
Eine methodisch fundierte Prognose würde erfordern, verschiedene Prognosemodelle miteinander zu vergleichen und deren Eignung kritisch zu hinterfragen. Aus meiner Masterarbeit weiß ich, dass – ähnlich wie bei Regressionsanalysen – vorab Verteilungen geprüft und Modellannahmen hinterfragt werden müssen, bevor eine belastbare Aussage (und Auswahl der geeignetesten Auswertungsmethode (in diesem Fall: Prognosemodell)) getroffen werden kann.
🧠 Codebeispiel: Python-Prognose mit Prophet
import pandas as pd
import sqlite3
import matplotlib.pyplot as plt
from prophet import Prophet
# Verbindung zur Datenbank
conn = sqlite3.connect("sales_analysis.db")
query = """
SELECT
strftime('%Y-%m', "Order Date") AS JahrMonat,
SUM(Sales) AS Umsatz,
SUM(Profit) AS Gewinn
FROM sales
GROUP BY JahrMonat
ORDER BY JahrMonat;
"""
df = pd.read_sql_query(query, conn)
conn.close()
# Daten aufbereiten
df["JahrMonat"] = pd.to_datetime(df["JahrMonat"])
df.set_index("JahrMonat", inplace=True)
# Prognosefunktion
def create_forecast(data, label, periods=24):
prophet_df = data.reset_index().rename(columns={"JahrMonat": "ds", label: "y"})
model = Prophet(yearly_seasonality=True, weekly_seasonality=False, daily_seasonality=False)
model.fit(prophet_df)
future = model.make_future_dataframe(periods=periods, freq="M")
forecast = model.predict(future)
return model, forecast
# Umsatz- und Gewinnprognose
model_sales, forecast_sales = create_forecast(df[["Umsatz"]], "Umsatz")
model_profit, forecast_profit = create_forecast(df[["Gewinn"]], "Gewinn")
# Visualisierung
plt.figure(figsize=(12, 6))
plt.plot(df.index, df["Umsatz"], label="Historischer Umsatz", color="royalblue")
plt.plot(forecast_sales["ds"], forecast_sales["yhat"], label="Prognose Umsatz (Prophet)", color="skyblue", linestyle="--")
plt.plot(df.index, df["Gewinn"], label="Historischer Gewinn", color="seagreen")
plt.plot(forecast_profit["ds"], forecast_profit["yhat"], label="Prognose Gewinn (Prophet)", color="limegreen", linestyle="--")
plt.title("📊 Umsatz- und Gewinnprognose für den Superstore (Prophet-Modell)")
plt.xlabel("Monat")
plt.ylabel("Betrag in USD")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()